Hackathon: GPT4-x-Alpaca Part 2: Creating a MUD with Evennia
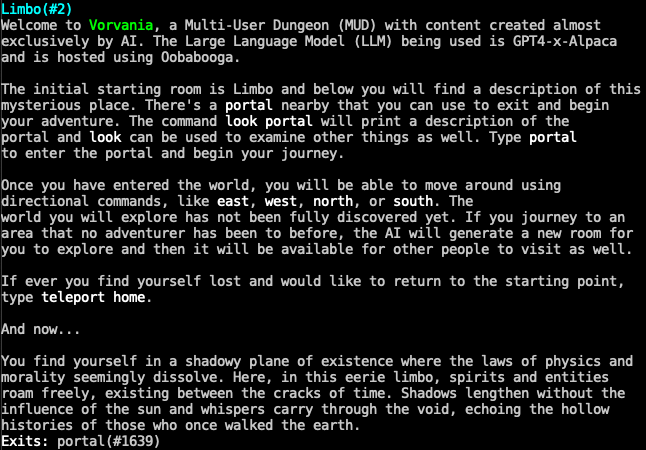
In part 1 of the hackathon I participated in at work, I set up the GPT4-x-Alpaca LLM with Oobabooga in an AWS EC2 instance. Next up in my hackathon journey was an attempt to make the LLM do something useful and fun. I’ve been casually interested in creating a Multi-User Dungeon or MUD for short. So for part 2 of the hackathon, I dug into the documentation for Evennia, a Python-based MUD game engine.
What is a Multi-User Dungeon? It’s a text-based, online world where players can create characters, level up fighting monsters, explore, and chat with each other. MUDs were pretty much the precursor to MMORPGs like World of Warcraft. Since MUDs are completely text-based and benefit from good story writing, I figured a MUD would be a good candidate for a LLM like GPT4-x-Alpaca to integrate with. My goal was to have the LLM provide all game descriptions and even dynamically generate rooms.
First, I needed to be able to send a request to the LLM via Python. Fortunately, Oobabooga already has a REST API built in that I only had to enable:
run_cmd("python server.py --chat --model-menu --wbits 4 --groupsize 128 --listen --extension api", environment=True)
Then when you run Oobabooga, you can see the REST endpoints:
INFO:Found the following quantized model: models/gpt4-x-alpaca-13b-native-4bit-128g/gpt-x-alpaca-13b-native-4bit-128g-cuda.pt
INFO:Loaded the model in 68.69 seconds.
Starting streaming server at ws://0.0.0.0:5005/api/v1/stream
INFO:Loading the extension "gallery"...
INFO:server listening on 0.0.0.0:5005
Starting API at http://0.0.0.0:5000/api
Running on local URL: http://0.0.0.0:7860
After starting Oobabooga with the REST API enabled, it was easy to send a request to the endpoint and receive an inference response from the model. One major caveat though: the REST API is stateless and there is no way currently to provide chat context in the request. So every request to the API is treated like the first request, meaning you’ll receive the same answers, unless you change up the prompt. This turned out to be a pretty big shortcoming, but I tried to make it work anyway. The other downside is the response time was roughly 10 seconds or more. Fairly slow if you want to dynamically generate rooms while people are exploring a game.
Next up was learning how to use Evennia to create a MUD. I wasn’t really sure what to expect from Evennia. I thought I would be writing a bunch of code, but you can actually do a surprising amount with very little coding knowledge. Evennia is built in Python and can definitely be extended using Python, but it was mostly designed to be a sort of sandbox environment. If you are logged in as a superuser or developer, you can create objects, add scripts, change descriptions, etc. from within the game itself. So for a basic MUD, very little programming is needed. Anything like combat or character stats will require programming, but assuming you have all the components previously created, building the world can be done from within the MUD itself.
I ended up writing what they call a batchcommand script to build the world. This means I created a create_world.ev file with a bunch of Evennia MUD commands that create several rooms and exits. With this command, my whole world can be created:
batchcommand world.create_world
Here’s the primary hub for the game, as generated by the model and inserted in the batchcommand file:
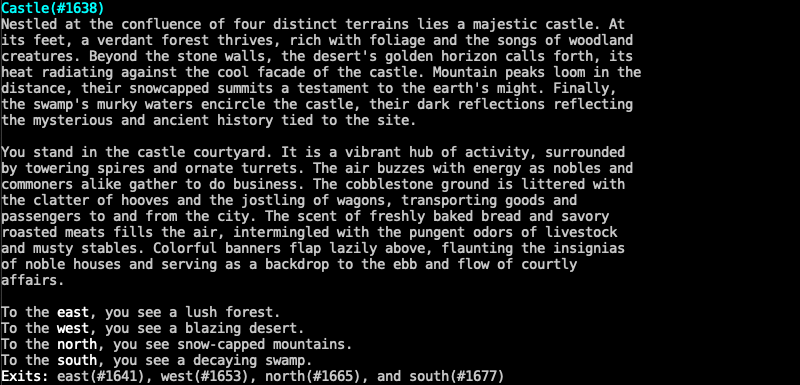
All the descriptions that went into the batchcommand file were responses to prompts I entered in Oobabooga. Even the name of the game, Vorvania, was generated by GPT4-x-Alpaca. This is all well and good, but it’s a very manual process. I wanted the user to be able to explore different regions and have the model generate all the descriptions. I wrote some simple Python code to send a request to the Oobabooga REST API:
uri = f'http://{host}:{port}/api/v1/generate'
context = "Below is an instruction that describes a task. Write a response that appropriately completes the request and, after response, please stop generation."
# random() is added to provide some randomness, since the api is stateless
p = f"{context}\n### Human:\n{random()} {prompt}\n### Assistant:\n"
request = {
'prompt': p,
'stopping_strings': ["\n### Human:"],
'max_new_tokens': 250,
'do_sample': True,
'temperature': 1.3,
'top_p': 0.1,
'typical_p': 1,
'repetition_penalty': 1.18,
'top_k': 40,
'min_length': 0,
'no_repeat_ngram_size': 0,
'num_beams': 1,
'penalty_alpha': 0,
'length_penalty': 1,
'early_stopping': False,
'seed': -1,
'add_bos_token': True,
'truncation_length': 2048,
'ban_eos_token': False,
'skip_special_tokens': True,
}
response = requests.post(uri, json=request)
if response.status_code == 200:
result = response.json()['results'][0]['text']
return result.strip()
Next, I added a pray command to the game, so you could “pray” to the gods of the world and receive a response from the model. Basically, it’s just an in-game interface to the model, with the addition of some prompt text to have the model respond as if it was a god.

The final task I worked on was making each of the 4 regions (forest, desert, mountains, swamp) auto-generate. I added some special room types that would automatically create exits to other rooms of the same type and request a description of the room from the model. This mostly works, but it’s unfortunately slow at around 10-15 seconds every time you enter a new room. Also, as I mentioned previously, I had trouble getting the model responses to differ significantly. I added some randomness to the prompts, but would still get very similar answers with only minor differences. I think with more time, I could get the model to do more, but not having chat context made it more difficult.
The full source code for the MUD proof-of-concept is available here:
https://github.com/eleniums/mud-ai
Regardless of these challenges, this whole project was a lot of fun! I was able to play with the latest new AI chat models and try my hand at building a MUD. These AI chat models have come a long way and, despite their current limitions with memory and speed, are pretty impressive as they are today. I look forward to seeing how AI chat bots improve over the next several years. They are already improving at the speed of light, it seems.