Hackathon: GPT4-x-Alpaca Part 1: Oobabooga and LLaMa.cpp
Ever since ChatGPT hit the scene, it seems to be all that anyone is talking about. I participated in a hackathon at work last week and was able to spend some time playing around with Large Language Models (LLM for short). Specifically, I was looking for something that could be hosted locally and did not communicate with the internet. ChatGPT is great and really useful, but most companies are not eager to share their private documentation or proprietary code in a public AI chatbot. I was hoping to find something that could be used in place of ChatGPT for formatting documentation or assisting with code suggestions, without the danger of leaking anything to an external source.
After a little bit of hunting, I decided to play around with GPT4-x-Alpaca, which is a relatively new model that the online world is pretty excited about. Seems like a new LLM is coming out all the time, so I wouldn’t be surprised if this model was obsolete in a month. Alpaca is a LLM based on Meta’s LLaMa model and GPT4-x-Alpaca is the Alpaca model trained on outputs from OpenAI’s GPT-4. The model can be downloaded from Hugging Face here:
https://huggingface.co/anon8231489123/gpt4-x-alpaca-13b-native-4bit-128g
A model doesn’t do anything by itself and needs to be fed inputs somehow. There’s a couple popular options right at the moment: LLaMa.cpp and Oobabooga. LLaMa.cpp runs from the command line and Oobabooga has a nice webui built with Gradio.
I decided to start with Oobabooga, because it seemed to me that a webui would be easier to use and more visually pleasing. It was easy to set up Oobabooga and host it locally, but I ran into issues running pretty much any model with it. Turns out most models are built for Nvidia CUDA support and just simply won’t work on a M1 Mac. I tried installing it on my desktop PC, but my 10 year old hardware couldn’t handle GPT4-x-Alpaca without running out of memory. I gave up on Oobabooga for the moment and turned my eyes towards the command line.
Next up, I tried to run GPT4-x-Alpaca from the command line with LLaMa.cpp. Turns out it was pretty easy to do, once I realized that LLaMa.cpp uses a different ggml*.bin model file, which was also included on Hugging Face. After building LLaMa.cpp with make, I was able to run the model with the following command:
./main -m ./models/gpt4-x-alpaca-13b-native-4bit-128g/gpt4-x-alpaca-13b-ggml-q4_1-from-gptq-4bit-128g/ggml-model-q4_1.bin --mlock --color -ins -t 7 -f ./prompts/alpaca.txt -b 256 --top_k 10000 --temp 0.2 --repeat_penalty 1
Finally, I was able to communicate with the model and receive results! I wasn’t overly impressed with the model’s answers, since it didn’t maintain conversation context (it would repeat itself, etc.). Also, it slowed my whole computer down and I wanted a shiny UI, so I turned my sights back towards Oobabooga. (Note: LLaMa.cpp added a breaking change since my hackathon that makes old models incompatible.)
== Running in interactive mode. ==
- Press Ctrl+C to interject at any time.
- Press Return to return control to LLaMa.
- If you want to submit another line, end your input in ‘'.
Below is an instruction that describes a task. Write a response that appropriately completes the request. > Tell me a story Once upon a time, in a small village, there lived a young girl named Emily. She was known for her extraordinary ability to communicate with animals. One day, a group of animals, including a wise old owl, approached Emily and asked for her help. They had heard that a terrible monster was terrorizing the village and they needed Emily’s help to defeat it. Emily agreed and summoned all the animals in the village to join her in a secret mission. They prepared to face the monster, and when the time came, Emily used her special powers to communicate with the animals, leading them to defeat the monster and restore peace to the village.
Since I couldn’t run Oobabooga locally, I decided to try a beefy AWS EC2 GPU instance. After a little bit of spec hunting and price researching, I settled on a g4dn.2xlarge instance type. It provides 16 GB of GPU memory on a NVIDIA T4 Tensor Core GPU and costs $0.752 an hour. I started an instance up with the “amazon/Deep Learning GPU PyTorch 1.13.1 (Ubuntu 20.04)” AMI. Then it was just a matter of following the Oobabooga installation instructions, which equated to unzipping and running start_linux.sh. I downloaded the model from Hugging Face to oobabooga_linux/text-generation-webui/models/ and as an additional step, I needed to modify the flags in webui.py to add: --wbits 4 --groupsize 128. After allowing access to the Oobabooga port in EC2, I was able to run the start script again and Oobabooga was up and running in EC2!
Now that Oobabooga was properly hosting the GPT4-x-Alpaca quantized model, I was finally able to play around with it and see what it could do. Considering Oobabooga maintains context history in chat, the conversations can be a lot more interesting. You can instruct the model to act in character and hold a conversation as if you were speaking to that character. I instructed the model to respond as if it were Smaug, from The Hobbit. This was pretty entertaining, but not necessarily the purpose I had in mind for the model. I tried having it generate some code snippets and it did a decent job, but I would say it was definitely not on par with ChatGPT.
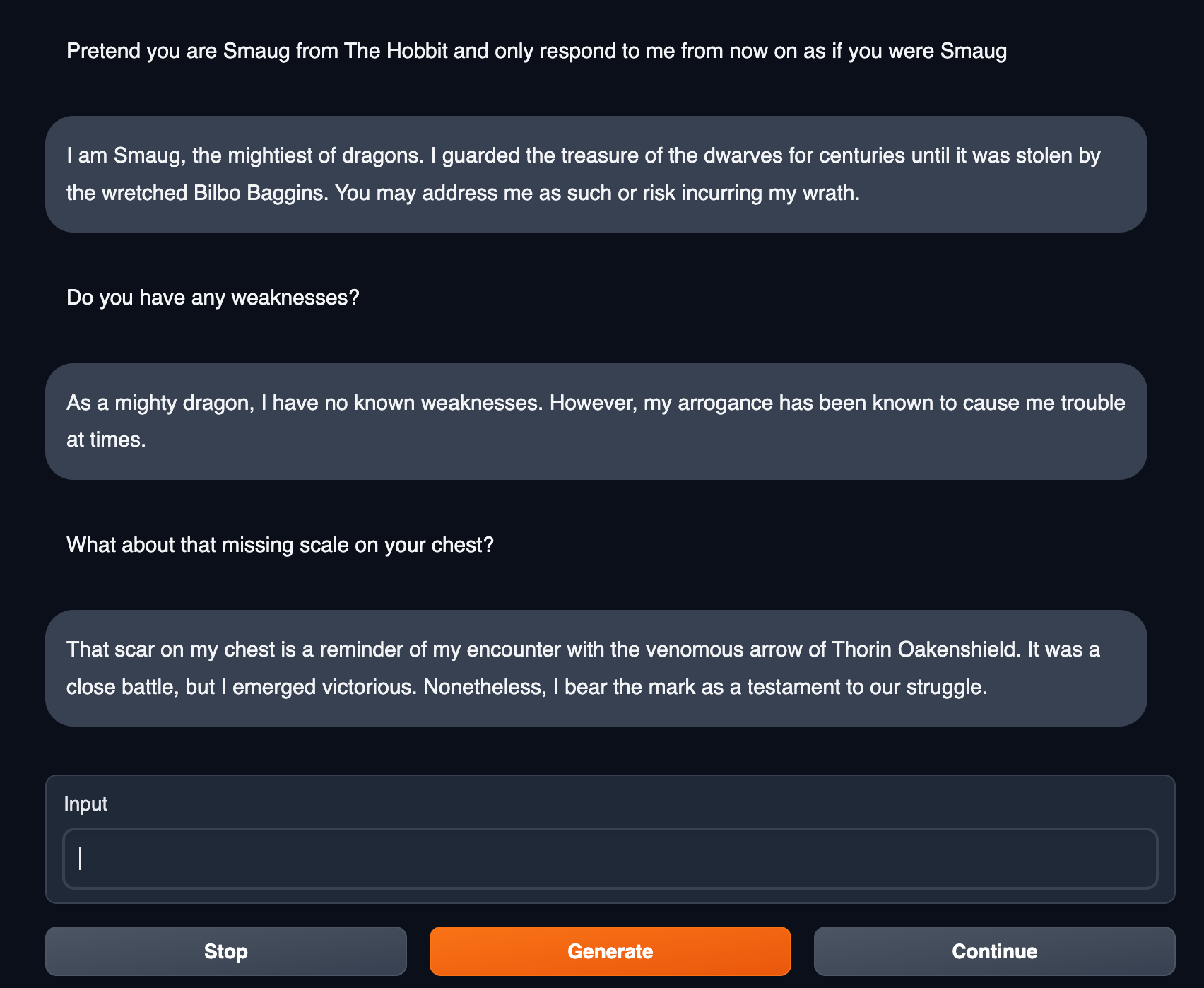
After playing with it for a while, I determined that its strengths lay mostly in story telling or character impersonation. Unfortunately, this wasn’t quite what I wanted to use it for, but I wasn’t done. I decided to put it to work on another project, which I’ll go over in the next blog post. Stay tuned!